

分析报告
注:由于课程设计要求上交演示文件,因此本文档中代码部分大多采用截图形式,以演示运行结果,所有代码均位于ipynb文件中,读者可自行查阅。笔者采用VSCode运行ipynb,文件中附带了项目所依赖的环境需求文件,读者使用
pip install -r requitrements.txt部署项目依赖相关包的环境后,使用Jupyter Notebook或任意可用编辑器运行即可。
一、概述
- 在本文中,参考林子雨老师的基于地震数据的Spark数据处理与分析与基于Spark的地震数据处理与分析,我们使用和鲸社区公开的地震数据集构建了一个模型来预测地震。该数据集包含数千个按时间、日期、纬度、经度、深度、震级等划分的地震。
- 项目使用pyspark进行数据分析与处理。
- 对于可视化方案,在以往的可视化项目中,已经使用过的方案有:Excel,matplotlib,Echarts,pyecharts,在考研后使用过tableau这一BI工具,因此在本次案例中,我将可视化方案放在了还未使用过的D3.js,Bokeh,Seaborn之中。D3.js毫无疑问的首先被排除了,没有像Echarts等封装好的关系图,更底层,高度的定制化,密密麻麻的的英文官方文档,一个简单图几百行的代码量,直接让我放弃了这个最漂亮最有想象力的可视化方案。因此可视化方案落在了Bokeh与Seaborn之中,虽然并不确定我们能否从数据中挖掘训练中我们想要的信息,但还是准备部署到服务器端,而Seaborn是不支持交互的,因此,我们将可视化方案定为了Bokeh。
Bokeh简介: Bokeh是一个专门针对Web浏览器的呈现功能的交互式可视化Python库。这是Bokeh与其它可视化库最核心的区别,它可以做出像D3.js简洁漂亮的交互可视化效果,但是使用难度低于D3.js,首先还是导入相关库:并且Bokeh有自己的数据结构ColumnDataSource,所以要先对数据进行转换,接着就是创建画布、添加数据及设置:Bokeh做出来的图是支持交互的,从官方给出的图来看Bokeh能作出很多比Pyecharts更精美的图,但是查找相关参数的设置上将会耗费一定时间。
二、目的
因此本项目的模型数据基于和鲸社区公开的地震数据集进行预测。
该数据集包括1965年初至2016年底的23412条数据,数据包含时间、日期、纬度、经度、深度、震级等划分的地震。我们的项目旨在根据 1965 年至 2016 年的历史数据预测即将发生的地震。用来创建模型的算法是 RandomForestRegressor。为了测试模型的准确性,我们选择使用 1965-2016 年的数据集作为训练数据,使用 2017 年的数据集作为测试数据,然后使用 RMSE 对其进行测量。如果 RMSE < 0.5,则该模型可被归类为预测地震的良好拟合和可靠模型。
三、设置和安装
- 首先,我们需要使用 PySpark 和 MongoDB 建立一个data pipeline架构。具体细节可查看我的文章。以下为大致流程。
- 安装 FindSpark、PySpark、PyMongo 等第三方库。可以使用命令
pip install library-name安装库,使用Anaconda Prompt亦可使用conda install library-name。 - 安装 Apache Spark,下载压缩文件,之后,在部署的目录中创建一个名为“Spark”的新文件夹,然后将下载的 zip 文件中的文件夹复制粘贴到 Spark 文件夹中。
- 安装 Apache Spark 后,在我的电脑->属性->高级系统设置->环境变量,新建变量SPARK_HOME,变量的值为Spark文件所在的目录。之后,单击变量“Path”,创建一个新变量为 %SPARK_HOME%\bin,然后单击 OK。
- 配置好 Spark home 之后,还需要配置的 Hadoop home。首先要下载文件“winutils.exe”,这个文件是在 Windows 中运行 Hadoop 所必需的。下载文件后,将其复制并粘贴到 Spark 文件夹内的“bin”文件夹中。然后回到我的电脑->属性->高级系统设置->环境变量单击新建,创建一个新的变量名称为HADOOP_HOME,该变量的值与SPARK_HOME相同。之后,单击变量“Path”,创建一个新变量为 %HADOOP_HOME%\bin,然后单击 OK。
- 安装 Java 8 JDK 。
- 打开cmd,键入“spark-shell”以测试安装是否成功。
- 下载MongoDB。本项目中,我们使用的是适用于 Windows 的 MongoDB 5.0.2。
- 可选,安装数据库工具NoSQLBooster
- 创建地震数据库。
- 安装 FindSpark、PySpark、PyMongo 等第三方库。可以使用命令
- 文件中附带了项目所依赖的环境需求文件,可以使用
pip install -r <path:> requitrements.txt来部署项目依赖的包的环境。
四、数据处理
1. 将 pyspark 与 Jupyter Notebook 集成
import findspark
findspark.init()import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import *
# Configure spark session
spark = SparkSession\
.builder\
.master('local[2]')\
.appName('quake_etl')\
.config('spark.jars.packages', 'org.mongodb.spark:mongo-spark-connector_2.12:2.4.1')\
.getOrCreate()完成pyspark 与 Jupyter Notebook 的集成。
2. 提取、转换、加载
训练数据
在 Jupyter Notebook 中成功运行 PySpark 后,从本地目录加载数据集。
# 加载数据集
df_load = spark.read.csv(r"C:\Users\Edwin\Downloads\database.csv", header=True)
# 查看 df_load
df_load.take(1)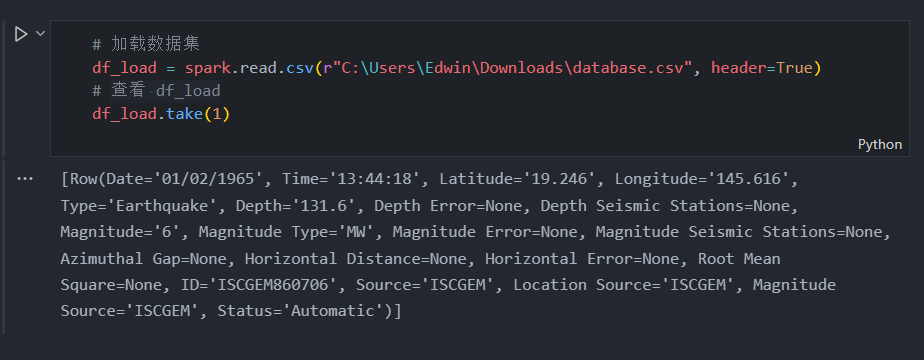
 加载数据集后,我们可以使用 df.take() 预览列,此函数有助于向我们显示特定行。在输出中,我们可以看到数据集包含许多列,因此我们不需要使用所有列。所以我们使用 df.drop() 删除不需要的列
加载数据集后,我们可以使用 df.take() 预览列,此函数有助于向我们显示特定行。在输出中,我们可以看到数据集包含许多列,因此我们不需要使用所有列。所以我们使用 df.drop() 删除不需要的列
# 删除不需要的字段
lst_dropped_columns = ['Depth Error', 'Time', 'Depth Seismic Stations','Magnitude Error','Magnitude Seismic Stations','Azimuthal Gap', 'Horizontal Distance','Horizontal Error',
'Root Mean Square','Source','Location Source','Magnitude Source','Status']
df_load = df_load.drop(*lst_dropped_columns)
# 查看 df_load
df_load.show(5)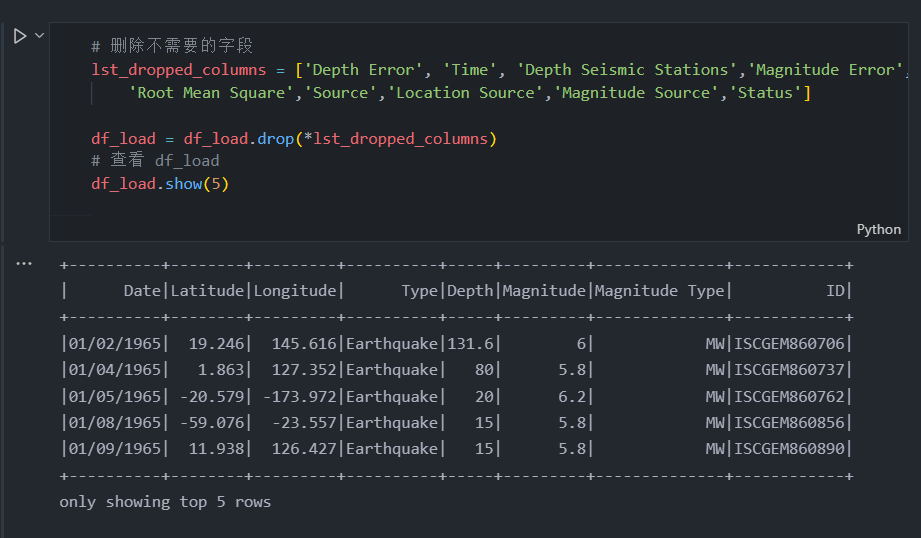
 现在我们只能看到我们需要操作的列,数据集现在更干净了。在我们对列进行排序之后,我们需要做的就是将“年份”列附加到数据框中。在我们将它添加到数据框之前,我们需要将“日期”列的类型转换为“时间戳”,因为“日期”的原始类型是“对象”,无法提取“对象”类型。所以我们可以简单地这样做:
现在我们只能看到我们需要操作的列,数据集现在更干净了。在我们对列进行排序之后,我们需要做的就是将“年份”列附加到数据框中。在我们将它添加到数据框之前,我们需要将“日期”列的类型转换为“时间戳”,因为“日期”的原始类型是“对象”,无法提取“对象”类型。所以我们可以简单地这样做:
# 创建年份字段并将其添加到数据框中
df_load = df_load.withColumn('Year', year(to_timestamp('Date', 'dd/MM/yyyy')))
# 查看 df_load
df_load.show(5)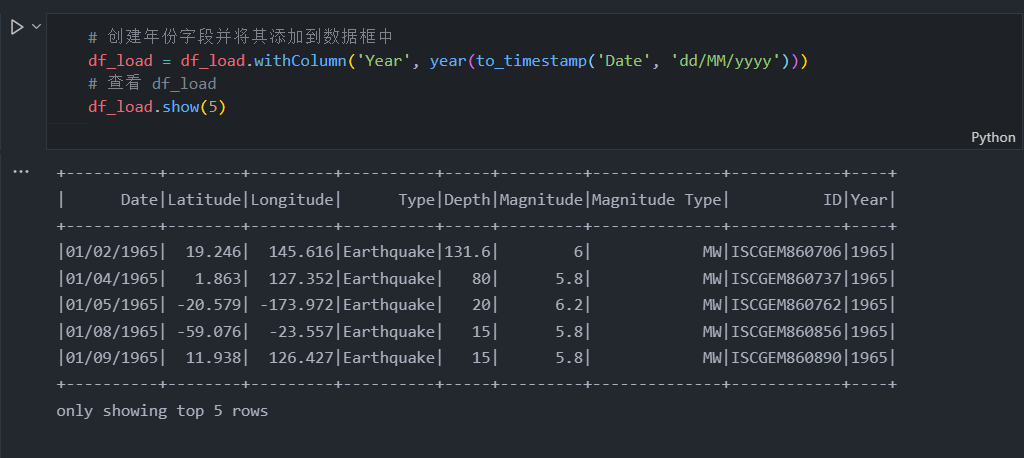
 在我们将“年份”列添加到数据框中之后,现在我们可以计算每年发生了多少次地震。我们可以使用 groupBy() 和 count():
在我们将“年份”列添加到数据框中之后,现在我们可以计算每年发生了多少次地震。我们可以使用 groupBy() 和 count():
# 使用年份字段构建地震频率数据框,并对每年进行计数
df_quake_freq = df_load.groupBy('Year').count().withColumnRenamed('count', 'Counts')
# 查看 df_quake_freq
df_quake_freq.show(5)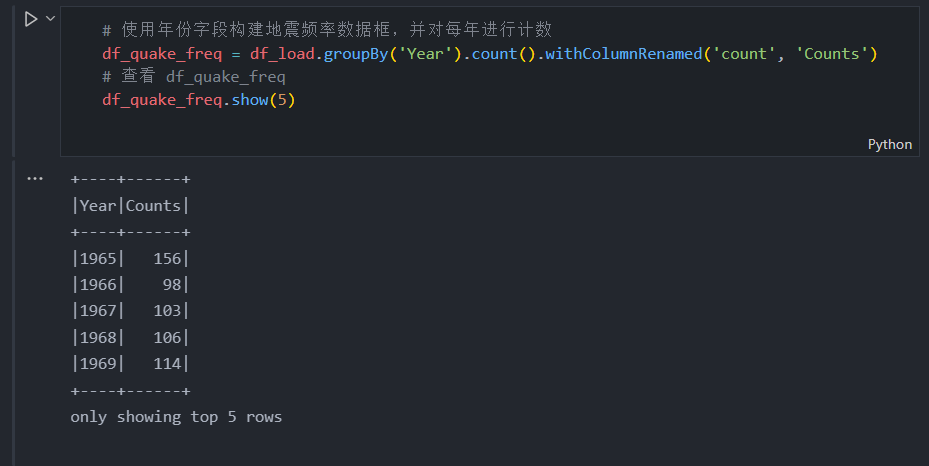
 根据数据框我们可以看到年份列没有按顺序排序,稍后我们可以处理这个问题。
根据数据框我们可以看到年份列没有按顺序排序,稍后我们可以处理这个问题。
在我们根据一年计算地震之后,现在我们可以检查列中每个数据的类型,如下所示:
# 查看 df_load schema
df_load.printSchema()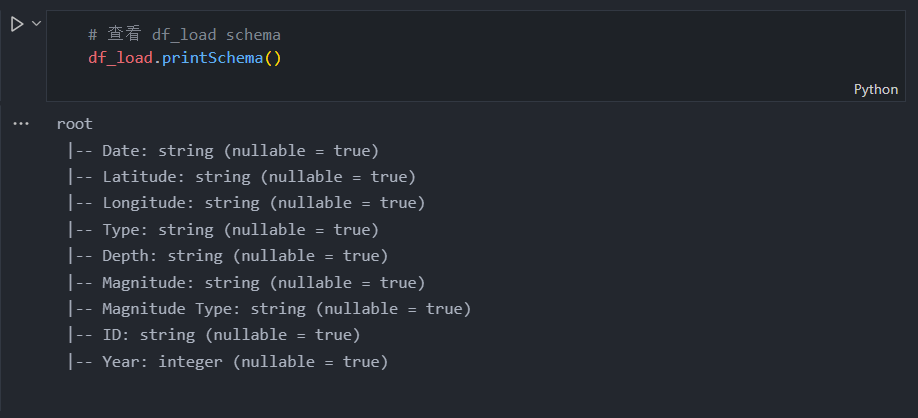
 正如我们从输出中看到的那样,列的大多数类型是一个无法连接的字符串。为此,我们需要使用 cast() 将我们需要的一些列从字符串转换为数字类型。
正如我们从输出中看到的那样,列的大多数类型是一个无法连接的字符串。为此,我们需要使用 cast() 将我们需要的一些列从字符串转换为数字类型。
# 将一些字段从字符串转换为数字类型
df_load = df_load.withColumn('Latitude', df_load['Latitude'].cast(DoubleType()))\
.withColumn('Longitude', df_load['Longitude'].cast(DoubleType()))\
.withColumn('Depth', df_load['Depth'].cast(DoubleType()))\
.withColumn('Magnitude', df_load['Magnitude'].cast(DoubleType()))
# 查看 df_load
df_load.show(5)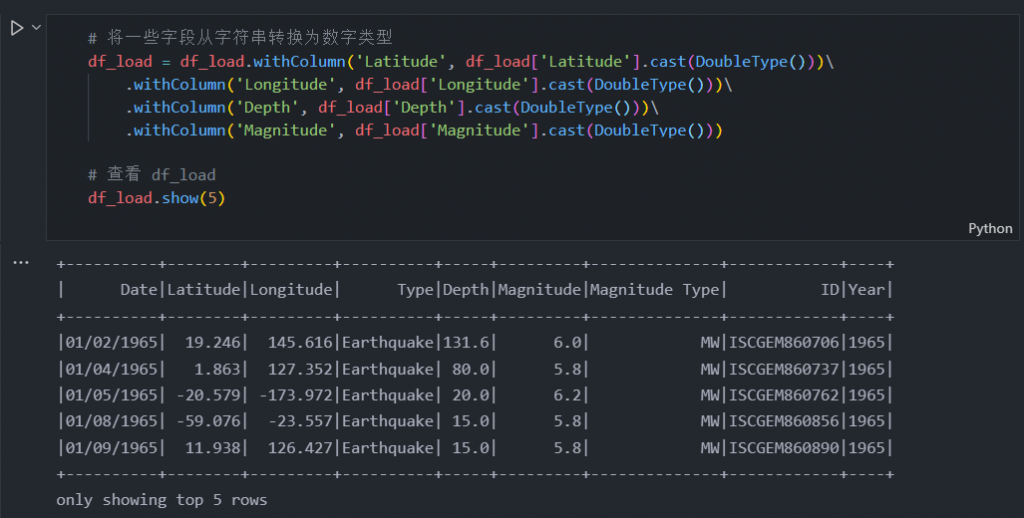

在我们将字符串列转换为数字之后,我们现在可以将 df_max 和 df_avg 连接到一个名为 df_quake_freq 的新变量中。
# 创建平均震级和最大震级字段,并添加到 df_quake_freq
df_max = df_load.groupBy('Year').max('Magnitude').withColumnRenamed('max(Magnitude)', 'Max_Magnitude')
df_avg = df_load.groupBy('Year').avg('Magnitude').withColumnRenamed('avg(Magnitude)', 'Avg_Magnitude')# 链接 df_max, 和 df_avg 到 df_quake_freq
df_quake_freq = df_quake_freq.join(df_avg, ['Year']).join(df_max, ['Year'])
# 查看 df_quake_freq
df_quake_freq.show(5)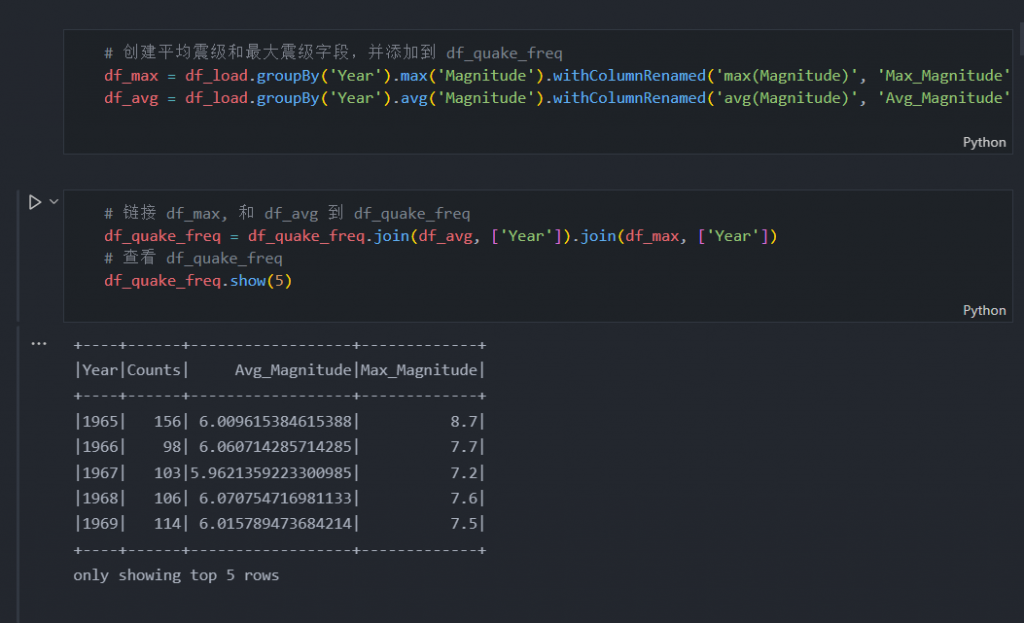

如果列已成功加入,我们可以做的下一件事是从数据框中删除所有缺失值。我们可以使用 dropna()。
# 删除空值
df_load.dropna()
df_quake_freq.dropna()
# 查看 dataframes
df_load.show(5)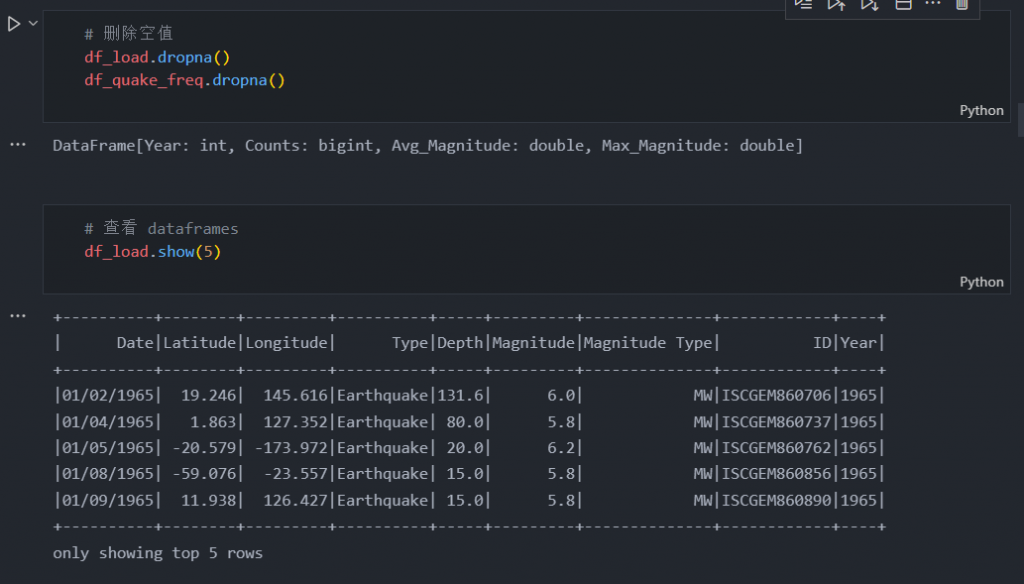
df_quake_freq.show(5)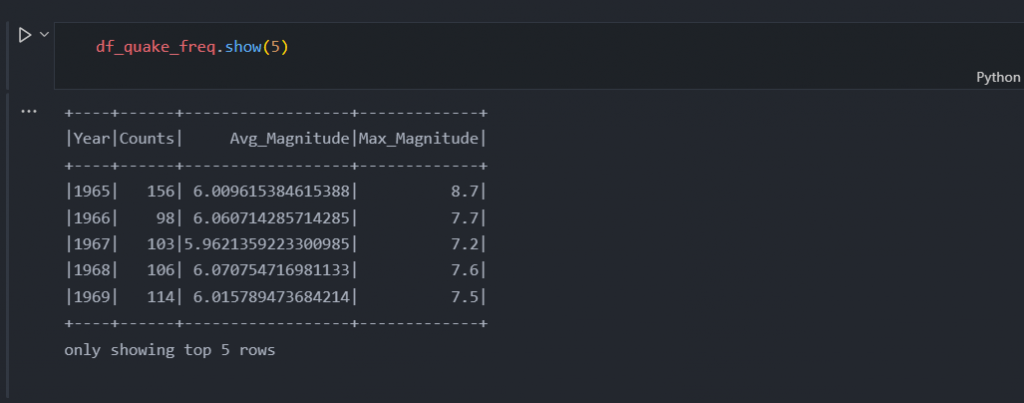
在我们删除空值后,数据就可以使用了,接下来我们需要做的就是将数据保存到 MongoDB 中。
# 在mongodb中构建表/集合
# 将 df_load 写入 mongodb
df_load.write.format('mongo')\
.mode('overwrite')\
.option('spark.mongodb.output.uri', 'mongodb://127.0.0.1:27017/Quake.quakes').save()# 将 df_quake_freq 写入 mongodb
df_quake_freq.write.format('mongo')\
.mode('overwrite')\
.option('spark.mongodb.output.uri', 'mongodb://127.0.0.1:27017/Quake.quake_freq').save()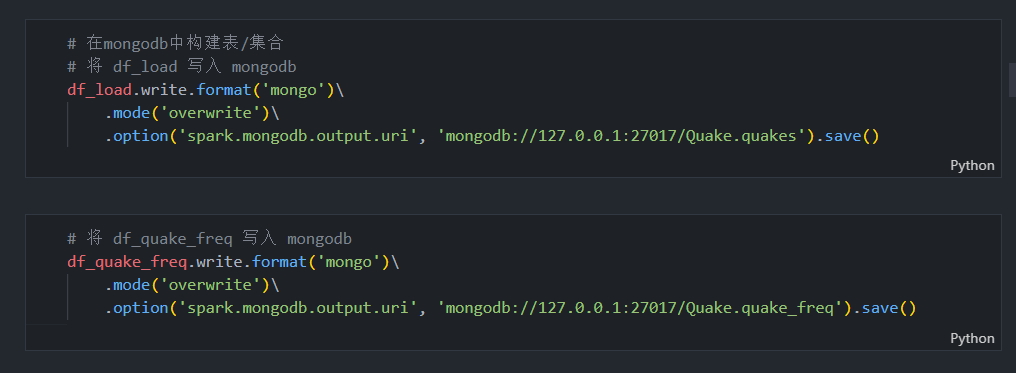

在保存了训练数据之后,我们可以做的下一件事就是加载测试数据。
测试数据
下载文件后,使用 Jupyter Notebook 加载测试和训练数据。
# 加载测试数据到 dataframe
df_test = spark.read.csv(r"C:\Users\Edwin\Downloads\query.csv", header=True)
# 查看 df_test
df_test.take(1)# 加载mongodb中的训练数据到 dataframe
df_train = spark.read.format('mongo')\
.option('spark.mongodb.input.uri', 'mongodb://127.0.0.1:27017/Quake.quakes').load()
# 查看 df_train
df_train.show(5)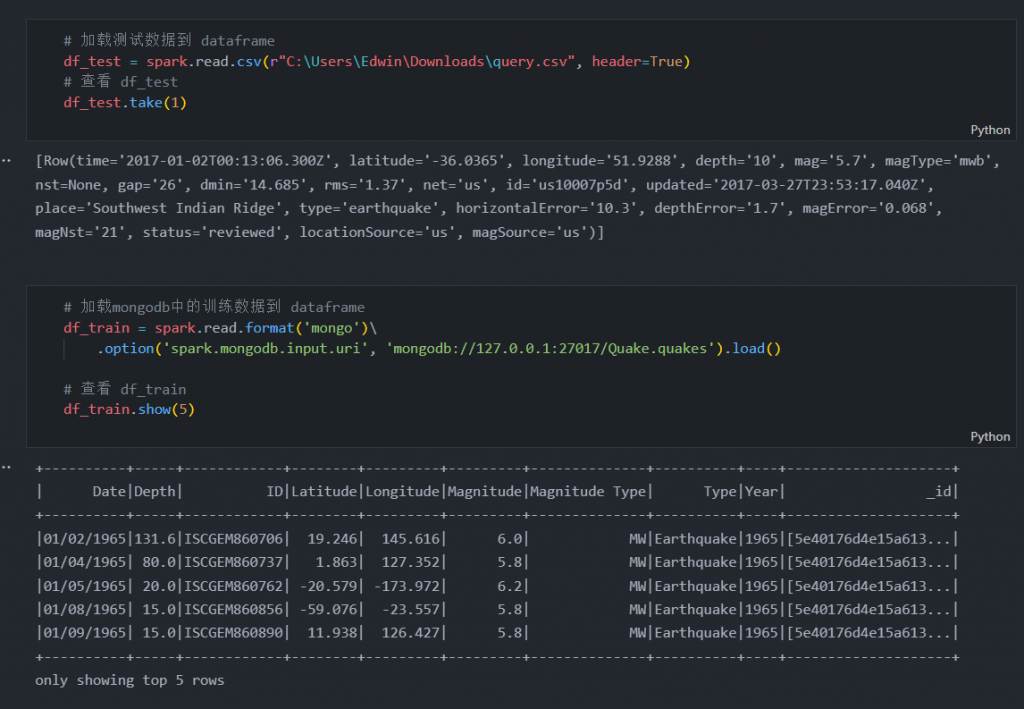
加载测试和训练数据后,我们可以做的下一件事是选择我们想要的列并重命名它们。
# 删除不需要的字段
df_test_clean = df_test['time', 'latitude', 'longitude', 'mag', 'depth']
# 查看 df_test_clean
df_test_clean.show(5)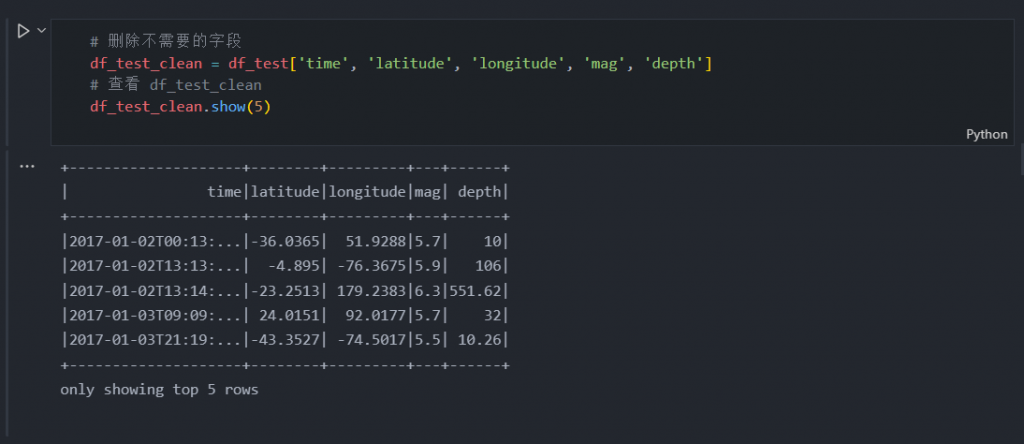
# 重命名字段
df_test_clean = df_test_clean.withColumnRenamed('time', 'Date')\
.withColumnRenamed('latitude', 'Latitude')\
.withColumnRenamed('longitude', 'Longitude')\
.withColumnRenamed('mag', 'Magnitude')\
.withColumnRenamed('depth', 'Depth')
# 查看 df_test_clean
df_test_clean.show(5)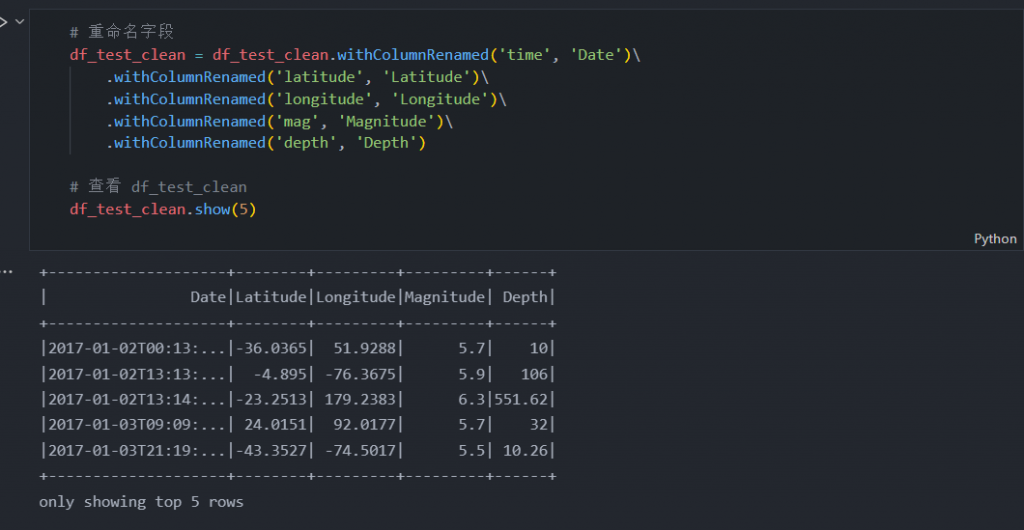
正如您所看到的,我们如何执行与之前对训练数据所做的相同的一组处理,因此现在我们检查测试数据中的字段类型并将其从字符串转换为数字。
# 将一些字符串字段转换为数字字段
df_test_clean = df_test_clean.withColumn('Latitude', df_test_clean['Latitude'].cast(DoubleType()))\
.withColumn('Longitude', df_test_clean['Longitude'].cast(DoubleType()))\
.withColumn('Depth', df_test_clean['Depth'].cast(DoubleType()))\
.withColumn('Magnitude', df_test_clean['Magnitude'].cast(DoubleType()))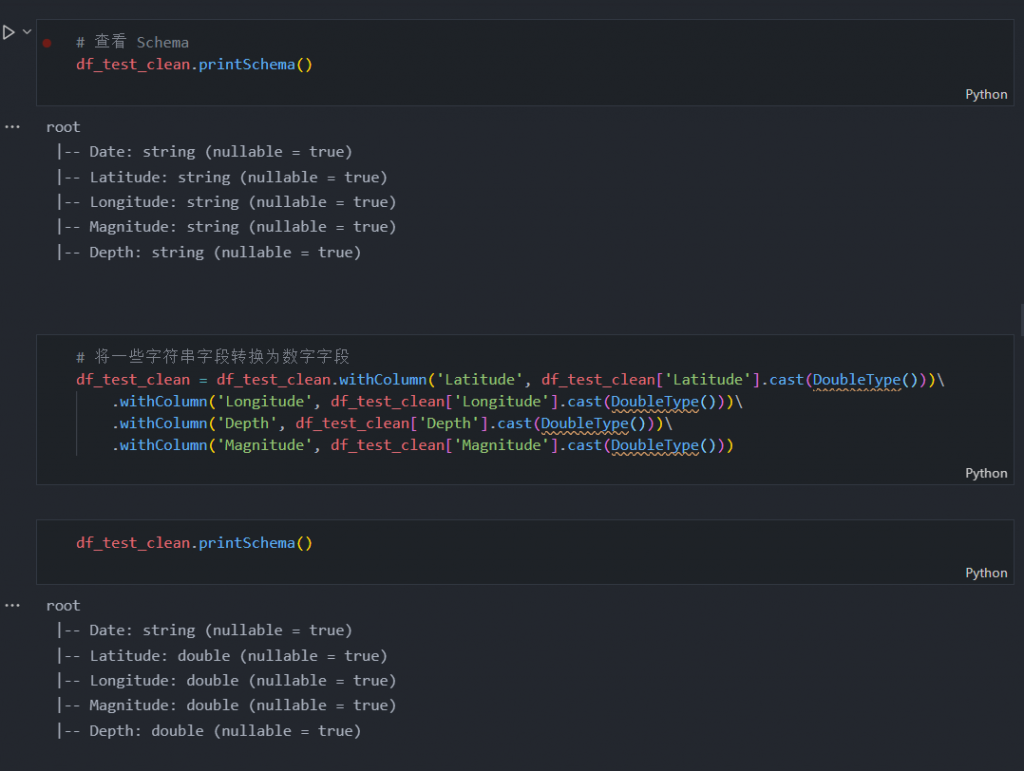
在我们需要的所有列都转换为数字之后,现在我们可以创建一个训练和测试数据框,并使用 dropna() 删除所有缺失值。
# 创建训练和测试数据 dataframes
df_testing = df_test_clean['Latitude', 'Longitude', 'Magnitude', 'Depth']
df_training = df_train['Latitude', 'Longitude', 'Magnitude', 'Depth']
# 查看 df_training
df_training.show(5)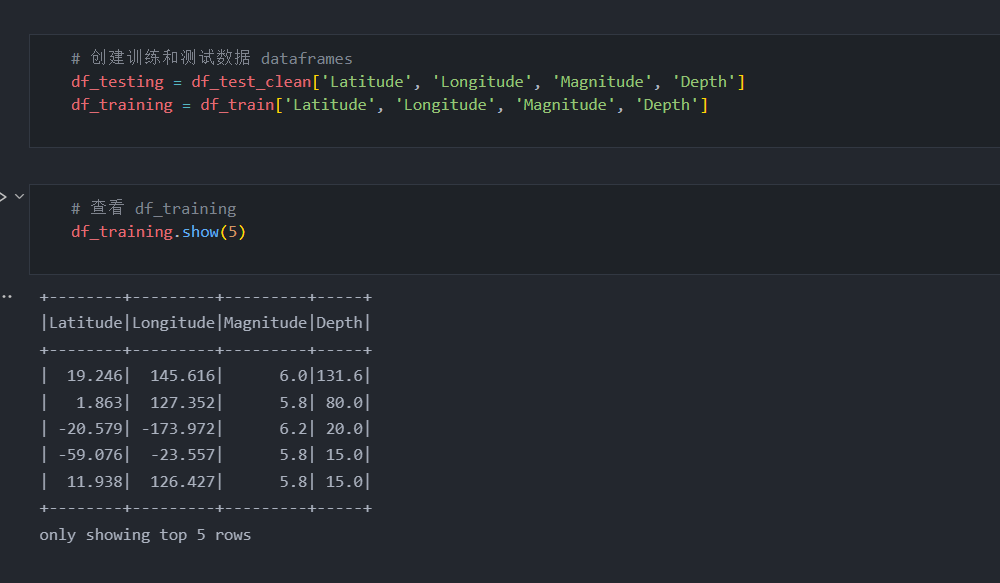
# 从数据帧中删除具有空值的记录
df_testing = df_testing.dropna()
df_training = df_training.dropna()
一旦我们删除了所有的空值并且数据框很整洁,现在我们就可以进入机器学习部分了。
五、机器学习
现在我们进入机器学习环节,在这个过程中,我们将导入一些必要的库来创建模型。
from pyspark.ml import Pipeline
from pyspark.ml.regression import RandomForestRegressor
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.evaluation import RegressionEvaluator导入所需的库后,我们可以创建模型。
# 选择要解析到模型中的特征,然后创建特征向量
assembler = VectorAssembler(inputCols=['Latitude', 'Longitude', 'Depth'], outputCol='features')
# 创建模型
model_reg = RandomForestRegressor(featuresCol='features', labelCol='Magnitude')
# 将assembler与Pipeline中的model连接起来
pipeline = Pipeline(stages=[assembler, model_reg])
# 训练模型
model = pipeline.fit(df_training)
# 做出预测
pred_results = model.transform(df_testing)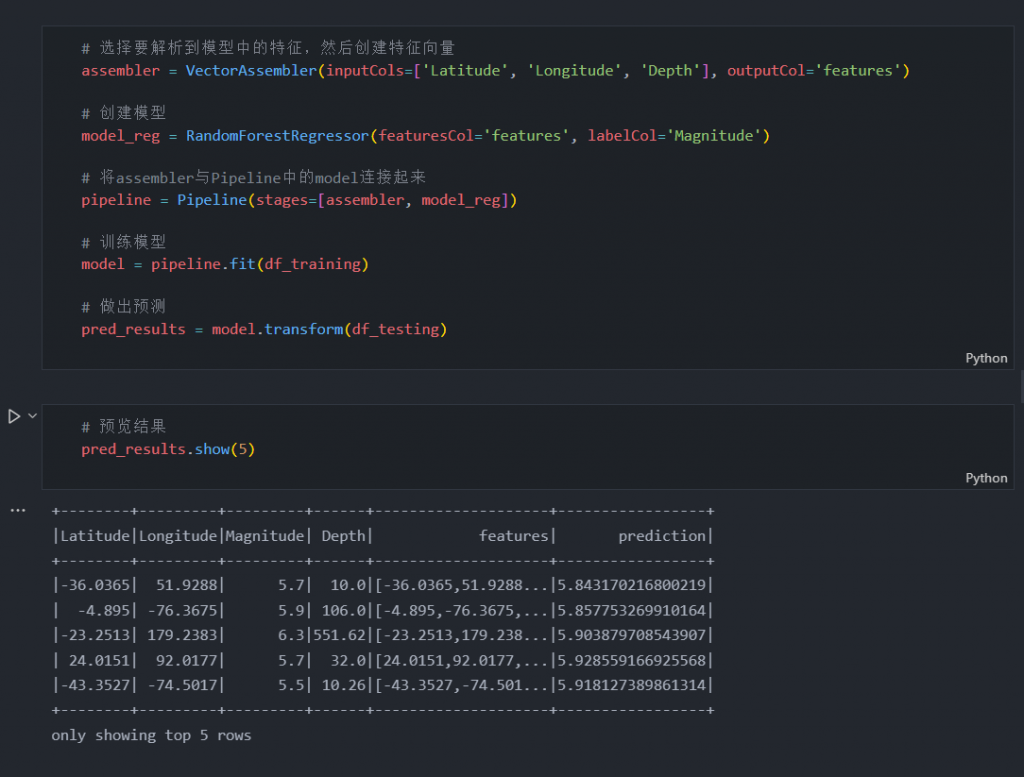
正如我们从上面的语法中看到的那样,为了进行预测,我们需要将纬度、经度和深度数据聚合到一个向量中,并将其存储到一个名为 features 的新列中。之后,预测结果将自动存储在预测列中。我们可以将幅度预测与测试数据的幅度进行比较,差异是可以容忍的。为了验证这个模型是否可靠,我们需要使用 RMSE 测试准确性。如果 RMSE 低于 0.5,则意味着该模型非常适合,我们可以使用它来进行预测。
# 评估模型
# rmse应小于0.5,模型才有用
evaluator = RegressionEvaluator(labelCol='Magnitude', predictionCol='prediction', metricName='rmse')
rmse = evaluator.evaluate(pred_results)
print('Root Mean Squared Error (RMSE) on test data = %g' % rmse)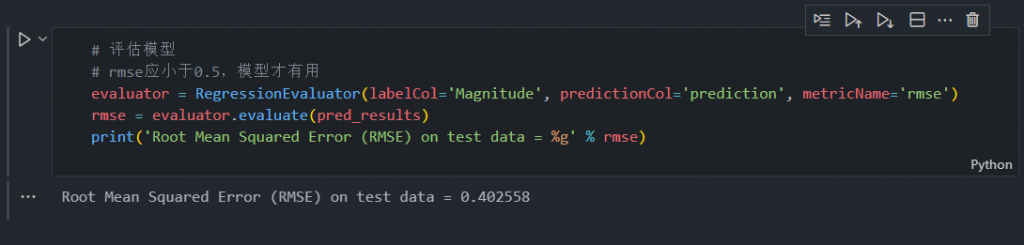
在我们计算 RMSE 后,结果为 0.402274,这意味着该模型拟合良好且可靠。
现在我们可以做的下一件事是创建一个用于预测的数据集,删除我们不需要的列,并重命名一些列。
# 创建预测数据集
df_pred_results = pred_results['Latitude', 'Longitude', 'prediction']
# 重命名预测字段
df_pred_results = df_pred_results.withColumnRenamed('prediction', 'Pred_Magnitude')
# 向预测数据集中添加更多列
df_pred_results = df_pred_results.withColumn('Year', lit(2017))\
.withColumn('RMSE', lit(rmse))
# 查看 df_pred_results
df_pred_results.show(5)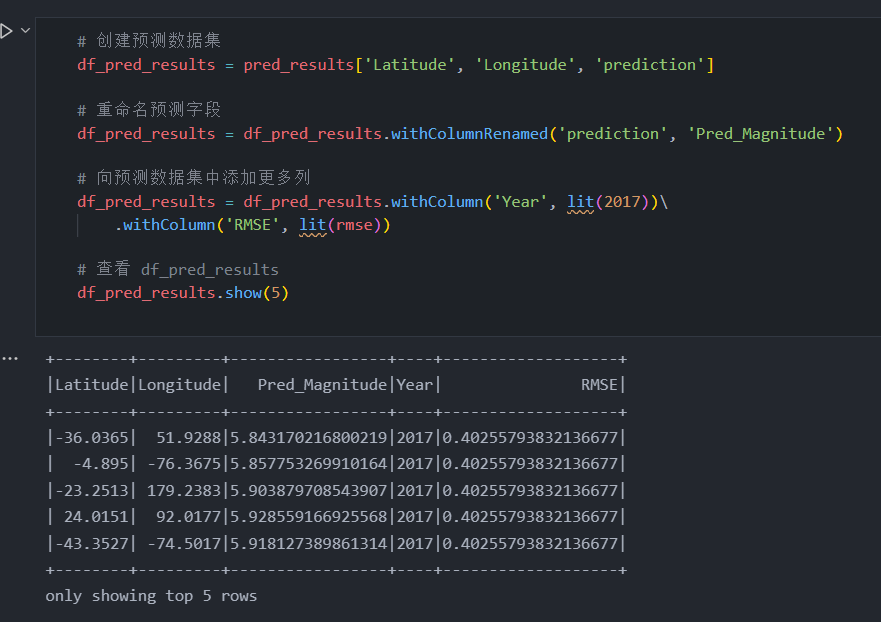
六、数据可视化
现在是有趣的部分,因为我们可以通过绘图看到我们的模型。在我们开始创建绘图之前,我们需要导入一些库。其中一个库是 Bokeh,它是可视化模型的重要部分。
import pandas as pd
from bokeh.io import output_notebook, output_file
from bokeh.plotting import figure, show, ColumnDataSource
from bokeh.models.tools import HoverTool
import math
from math import pi
from bokeh.palettes import Category20c
from bokeh.transform import cumsum
from bokeh.tile_providers import CARTODBPOSITRON
from bokeh.themes import built_in_themes
from bokeh.io import curdoc
from pymongo import MongoClient导入库后,我们可以做的下一件事是创建自定义读取函数。这部分对于从 MongoDB 读取数据很重要。
def read_mongo(host='127.0.0.1', port=27017, username=None, password=None, db='Quake', collection='pred_results'):
mongo_uri = 'mongodb://{}:{}/{}.{}'.format(host, port, db, collection)
# 链接数据库
conn = MongoClient(mongo_uri)
db = conn[db]
# 从集合中选择所有记录
cursor = db[collection].find()
# 创建 dataframe
df = pd.DataFrame(list(cursor))
# 删除 _id 字段
del df['_id']
return dfdf_quakes = read_mongo(collection='quakes')
df_quake_freq = read_mongo(collection='quake_freq')
df_quake_pred = read_mongo(collection='pred_results')然后,我们提取 2016 年的数据。
df_quakes_2016 = df_quakes[df_quakes['Year'] == 2016]
# 查看 df_quakes_2016
df_quakes_2016.head()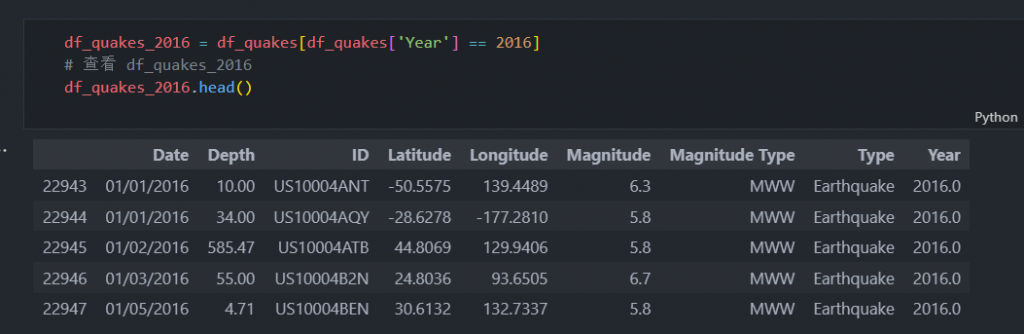
然后键入 output_notebook 以验证 BokehJS 是否已加载到 Jupyter Notebook 中。

好的,在我们创建 2016 年的数据集之后,我们现在可以做的下一件事是创建一个函数来设置我们的绘图样式。要设置绘图的样式,可以简单地执行以下操作:
def style(p):
# Title
p.title.align='center'
p.title.text_font_size='20pt'
p.title.text_font='serif'
# Axis titles
p.xaxis.axis_label_text_font_size='14pt'
p.xaxis.axis_label_text_font_style='bold'
p.yaxis.axis_label_text_font_size='14pt'
p.yaxis.axis_label_text_font_style='bold'
# Tick labels
p.xaxis.major_label_text_font_size='12pt'
p.yaxis.major_label_text_font_size='12pt'
# 图例
p.legend.location='top_left'
return p在我们创建了自定义样式函数之后,现在我们可以创建地理地图了。使用 Geo Map,我们可以看到我们的模型应用于地球地图。语法很长,所以我将引用下面的代码:
def plotMap():
lat = df_quakes_2016['Latitude'].values.tolist()
lon = df_quakes_2016['Longitude'].values.tolist()
pred_lat = df_quake_pred['Latitude'].values.tolist()
pred_lon = df_quake_pred['Longitude'].values.tolist()
lst_lat = []
lst_lon = []
lst_pred_lat = []
lst_pred_lon = []
i=0
j=0
# 将 Lat 和 Long 转换为 merc_projection 格式
for i in range(len(lon)):
r_major = 6378137.000
x = r_major * math.radians(lon[i])
scale = x/lon[i]
y = 180.0/math.pi * math.log(math.tan(math.pi/4.0 +
lat[i] * (math.pi/180.0)/2.0)) * scale
lst_lon.append(x)
lst_lat.append(y)
i += 1
# 将预测的 lat 和 long 转换为 merc_projection 格式
for j in range(len(pred_lon)):
r_major = 6378137.000
x = r_major * math.radians(pred_lon[j])
scale = x/pred_lon[j]
y = 180.0/math.pi * math.log(math.tan(math.pi/4.0 +
pred_lat[j] * (math.pi/180.0)/2.0)) * scale
lst_pred_lon.append(x)
lst_pred_lat.append(y)
j += 1
df_quakes_2016['coords_x'] = lst_lat
df_quakes_2016['coords_y'] = lst_lon
df_quake_pred['coords_x'] = lst_pred_lat
df_quake_pred['coords_y'] = lst_pred_lon
# 缩放
df_quakes_2016['Mag_Size'] = df_quakes_2016['Magnitude'] * 4
df_quake_pred['Mag_Size'] = df_quake_pred['Pred_Magnitude'] * 4
# 为ColumnDataSource对象创建数据源
lats = df_quakes_2016['coords_x'].tolist()
longs = df_quakes_2016['coords_y'].tolist()
mags = df_quakes_2016['Magnitude'].tolist()
years = df_quakes_2016['Year'].tolist()
mag_size = df_quakes_2016['Mag_Size'].tolist()
pred_lats = df_quake_pred['coords_x'].tolist()
pred_longs = df_quake_pred['coords_y'].tolist()
pred_mags = df_quake_pred['Pred_Magnitude'].tolist()
pred_year = df_quake_pred['Year'].tolist()
pred_mag_size = df_quake_pred['Mag_Size'].tolist()
# 创建列数据源
cds = ColumnDataSource(
data=dict(
lat=lats,
lon=longs,
mag=mags,
year=years,
mag_s=mag_size
)
)
pred_cds = ColumnDataSource(
data=dict(
pred_lat=pred_lats,
pred_long=pred_longs,
pred_mag=pred_mags,
year=pred_year,
pred_mag_s=pred_mag_size
)
)
# Tooltips
TOOLTIPS = [
("Year", " @year"),
("Magnitude", " @mag"),
("Predicted Magnitude", " @pred_mag")
]
# Create figure
p = figure(title='Earthquake Map',
plot_width=2300, plot_height=450,
x_range=(-2000000, 6000000),
y_range=(-1000000, 7000000),
tooltips=TOOLTIPS)
p.circle(x='lon', y='lat', size='mag_s', fill_color='#cc0000', fill_alpha=0.7,
source=cds, legend='Quakes 2016')
# 为预测的地震添加圆圈
p.circle(x='pred_long', y='pred_lat', size='pred_mag_s', fill_color='#ccff33', fill_alpha=7.0,
source=pred_cds, legend='Predicted Quakes 2017')
p.add_tile(CARTODBPOSITRON)
# 为地图绘图设置样式
# Title
p.title.align='center'
p.title.text_font_size='20pt'
p.title.text_font='serif'
# Legend
p.legend.location='bottom_right'
p.legend.background_fill_color='black'
p.legend.background_fill_alpha=0.8
p.legend.click_policy='hide'
p.legend.label_text_color='white'
p.xaxis.visible=False
p.yaxis.visible=False
p.axis.axis_label=None
p.axis.visible=False
p.grid.grid_line_color=None
#show(p)
return p
#plotMap() 现在运行语法后,将会有带有点的地图输出。绿点代表 2017 年的预测地震,红点代表 2016 年的地震。
截图示例如下:
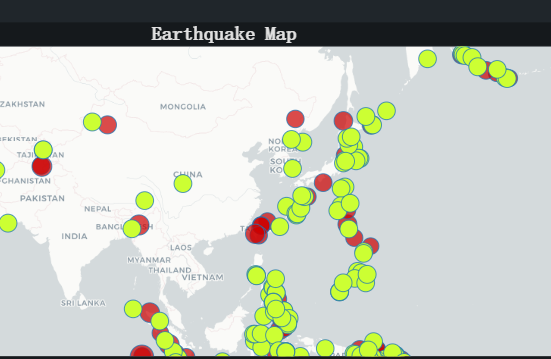
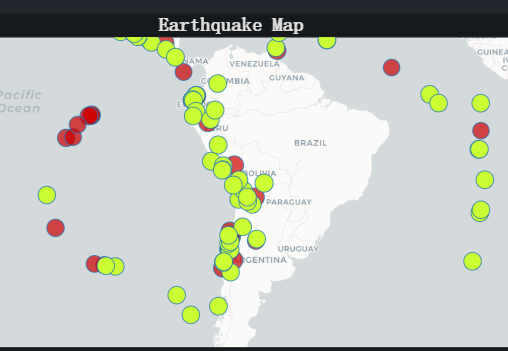
好的,在我们创建了地理地图之后,我们可以做的下一件事就是创建一个条形图。在此条形图中,我们将可视化每年的地震频率。
# 创建条形图
def plotBar():
# 加载数据源
cds = ColumnDataSource(data=dict(
yrs = df_quake_freq['Year'].values.tolist(),
numQuakes = df_quake_freq['Counts'].values.tolist()
))
# Tooltip
TOOLTIPS = [
('Year', ' @yrs'),
('Number of earthquakes', ' @numQuakes')
]
barChart = figure(title='Frequency of Earthquakes by Year',
plot_height=400,
plot_width=1150,
x_axis_label='Years',
y_axis_label='Number of Occurances',
x_minor_ticks=2,
y_range=(0, df_quake_freq['Counts'].max() + 100),
toolbar_location=None,
tooltips=TOOLTIPS)
barChart.vbar(x='yrs', bottom=0, top='numQuakes',
color='#cc0000', width=0.75,
legend='Year', source=cds)
barChart = style(barChart)
#show(barChart)
return barChart
#plotBar()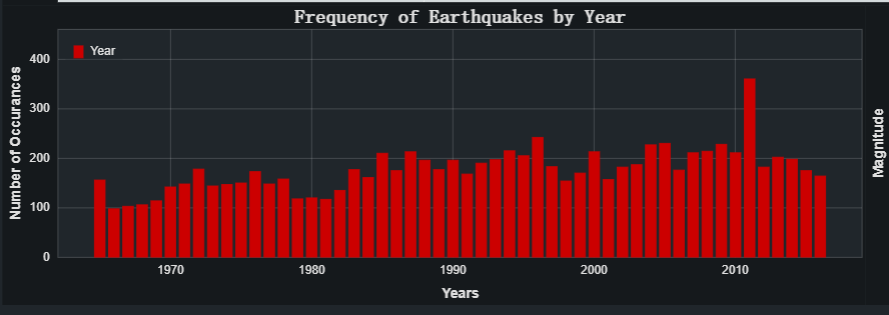
条形图告诉我们每年地震的趋势如何,根据图表我们可以看到 2010 年是地震发生次数最多的一年。
在我们创建了地震频率的条形图之后,现在我们将创建折线图来了解每年的震级趋势。
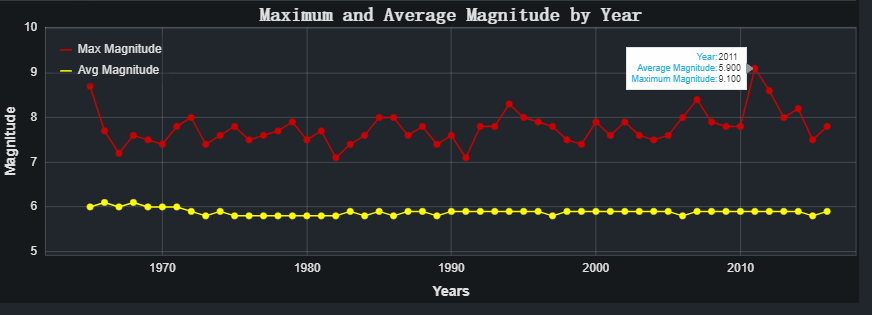
# 创建一个震级图
def plotMagnitude():
# 加载数据源
cds = ColumnDataSource(data=dict(
yrs = df_quake_freq['Year'].values.tolist(),
avg_mag = df_quake_freq['Avg_Magnitude'].round(1).values.tolist(),
max_mag = df_quake_freq['Max_Magnitude'].values.tolist()
))
# Tooltip
TOOLTIPS = [
('Year', ' @yrs'),
('Average Magnitude', ' @avg_mag'),
('Maximum Magnitude', ' @max_mag')
]
mp = figure(title='Maximum and Average Magnitude by Year',
plot_width=1150, plot_height=400,
x_axis_label='Years',
y_axis_label='Magnitude',
x_minor_ticks=2,
y_range=(5, df_quake_freq['Max_Magnitude'].max() + 1),
toolbar_location=None,
tooltips=TOOLTIPS)
mp.line(x='yrs', y='max_mag', color='#cc0000', line_width=2, legend='Max Magnitude', source=cds)
mp.circle(x='yrs', y='max_mag', color='#cc0000', size=8, fill_color='#cc0000', source=cds)
mp.line(x='yrs', y='avg_mag', color='yellow', line_width=2, legend='Avg Magnitude', source=cds)
mp.circle(x='yrs', y='avg_mag', color='yellow', size=8, fill_color='yellow', source=cds)
mp = style(mp)
#show(mp)
return mp
#plotMagnitude()
从折线图可以看出,如果我们调查该震级与1965 年至 2016 年之间的最高震级2011 年东北地震和海啸有关,我们可以知道 2011 年发生了里氏 9.1 级地震。
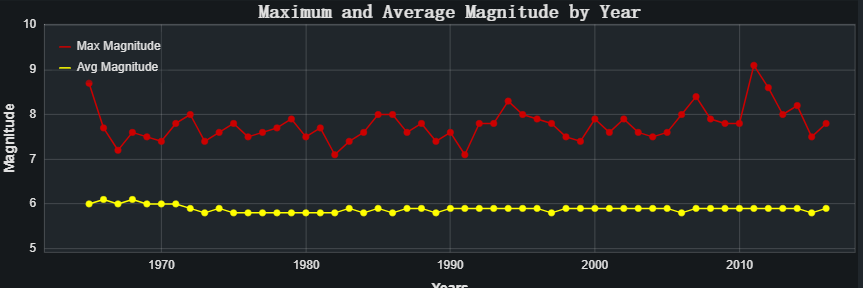
七、总结
谁念西风独自凉,萧萧黄叶闭疏窗,沉思往事立残阳。
岁月荏苒,不知不觉间已经来到了大学的末班车,数一数掌握的知识,却也没多少能拿得出手。
最后的实训项目选择了这一地震预测的项目,经历了许多挫折,终也有所收获。
虽仅仅做了数据预测和以及趋势的总结,确也认真走过了pyspark的处理流程,运用了MLlib的相关知识;虽低估了bokeh的难度,但却也新学习了这一python可视化库,实现出了一些小图。
被酒莫惊春睡重,赌书消得泼茶香,当时只道是寻常。
大学已至末尾,校园将入职场,人生浮华,路途漫长,只望初心不改,乘风破浪。
Comments NOTHING