

概述
data pipeline或也可以称为 ETL 管道是将原始数据转换为业务问题的可操作答案的一组流程。数据科学管道使数据验证过程自动化;提取、转换、加载(ETL),机器学习和建模,修订和输出,例如到数据仓库或可视化平台(Snowflake,n.d.)。
好的,现在我将向您展示如何使用 PySpark 和 MongoDB 设置数据管道架构。
设置和安装
1. 首先,我们需要安装 FindSpark、PySpark、PyMongo 等第三方库。您可以使用命令 pip install library-name 安装库,如果您使用的是 Anaconda Prompt,则可以使用 conda install library-name。
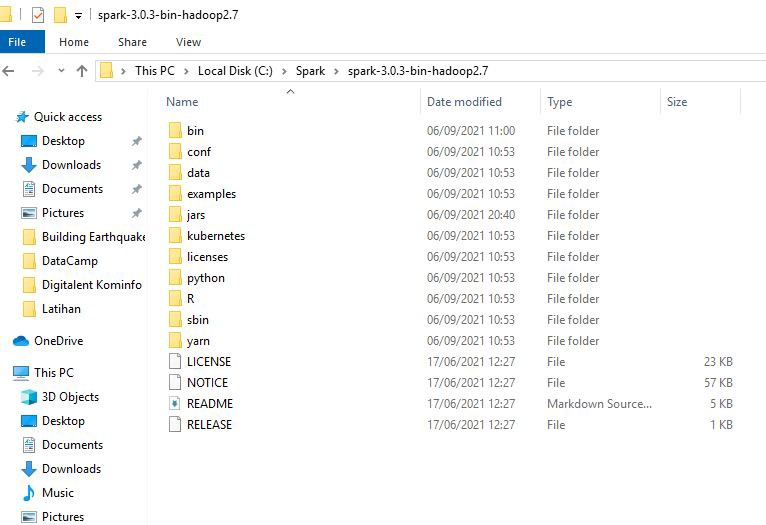
2. 其次,我们需要安装 Apache Spark,您可以从这里安装。之后,在 C:// 目录中创建一个名为“Spark”的新文件夹,然后将下载的 zip 文件中的文件夹复制粘贴到 Spark 文件夹中。
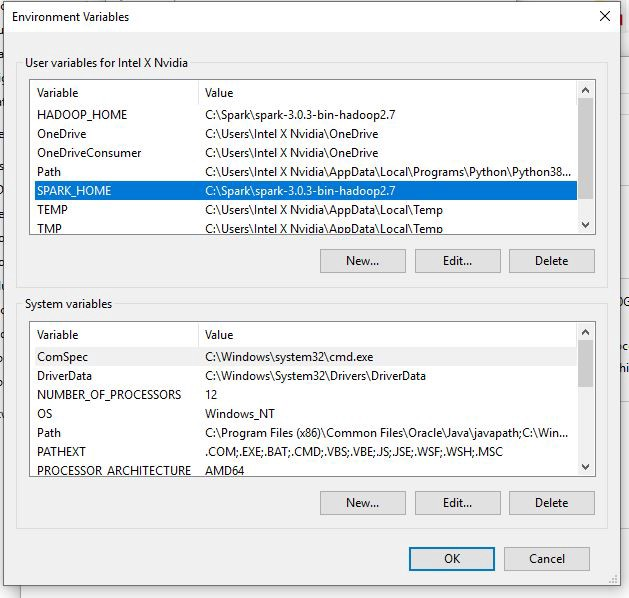
3. 安装 Apache Spark 后,现在我们需要配置 Spark 主环境以在 Windows 中运行 Spark。首先,进入这台电脑->属性->高级系统设置->环境变量,然后点击新建,新建一个变量名称为SPARK_HOME,变量的值就是Spark文件所在的目录,例如:“C:\ Spark\spark-3.0.3-bin-hadoop2.7”。之后,单击变量“Path”,创建一个新变量为 %SPARK_HOME%\bin,然后单击 OK。
4. 配置好 Spark home 之后,现在我们需要配置我们的 Hadoop home。我们需要做的第一件事是从这里下载文件“winutils.exe”,这个文件是在 Windows 中运行 Hadoop 所必需的。下载文件后,将其复制并粘贴到 Spark 文件夹内的“bin”文件夹中。现在回到这台PC->属性->高级系统设置->环境变量单击新建,创建一个新的变量名称为HADOOP_HOME,该变量的值与SPARK_HOME相同。之后,单击变量“Path”,创建一个新变量为 %HADOOP_HOME%\bin,然后单击 OK。
5. 一旦我们安装了 Spark 和 Hadoop,我们现在可以做的就是从这里安装 Java 8 JDK 。
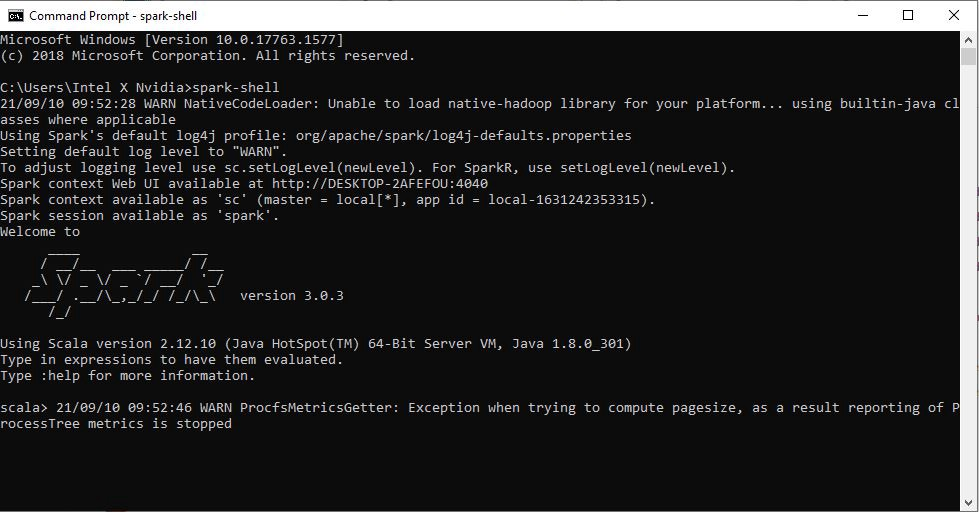
6. 在我们安装了 Spark 和 Java 之后,现在是时候检查我们的 Spark 是否安装和配置正确了。以管理员身份打开命令提示符,然后键入“spark-shell”。如果我们看到欢迎消息,恭喜 Spark 已成功安装在我们的机器上。如果不是,请在 C:// 中创建一个新文件夹为“tmp”,然后在其中创建一个新文件夹为“hive”,如果您使用的是旧版本的 Spark,则它是可选的。
7. Spark运行成功后,接下来我们需要下载MongoDB,并选择一个社区服务器。在这个项目中,我使用的是适用于 Windows 的 MongoDB 5.0.2。当您安装 MongoDB 时,您会遇到服务器自定义设置,供个人使用只需将其设为默认值,不要更改任何内容。安装完MongoDB后,打开安装目录,打开Mongo.exe,输入“db”,如果输出为“test”,则说明MongoDB安装成功。
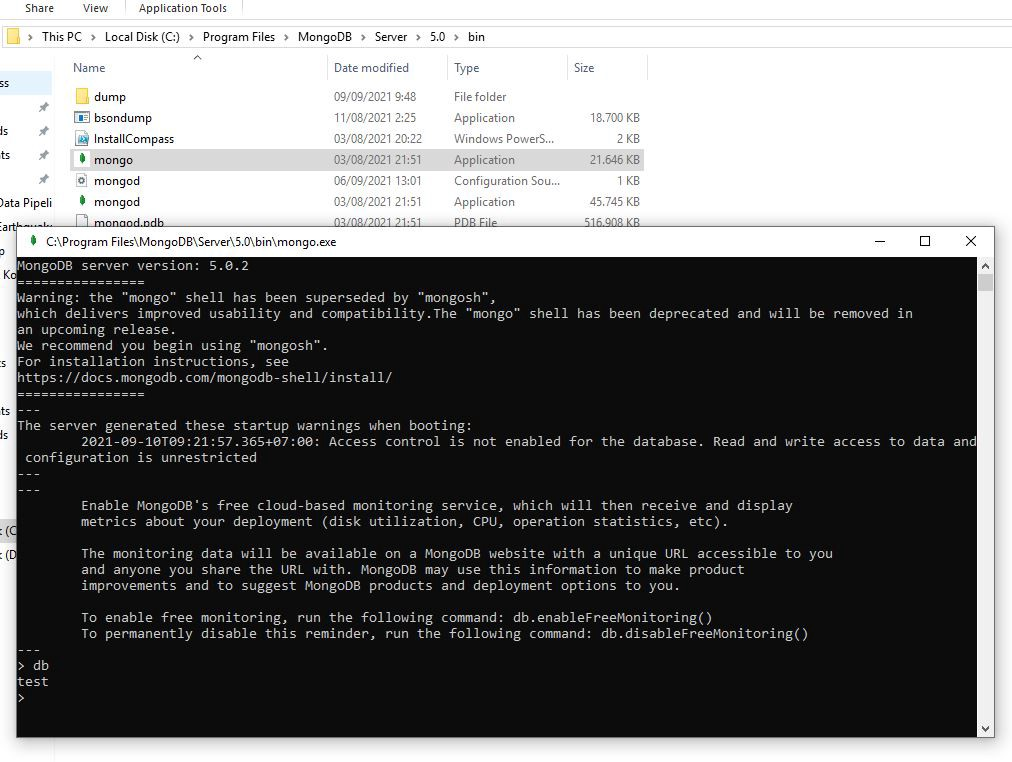
8. 只要我们知道与 MongoDB 交互,我们所能做的就是使用对用户不太友好的命令行,因此我们需要一个工具来处理这种情况。我们将使用的软件是NoSQLBooster,但如果您更喜欢使用命令行也没问题。一旦我们已经安装了 NoSQLBooster,接下来我们需要做的是建立连接,打开 NoSQLBooster->File->Connect->Create->Default settings->Test Connection。连接成功后,我们需要在 localhost 下创建一个数据库。您必须右键单击本地主机,然后创建一个数据库。您可以随意命名数据库,在这种情况下,我将数据库命名为“Quake”,用于下一个项目。
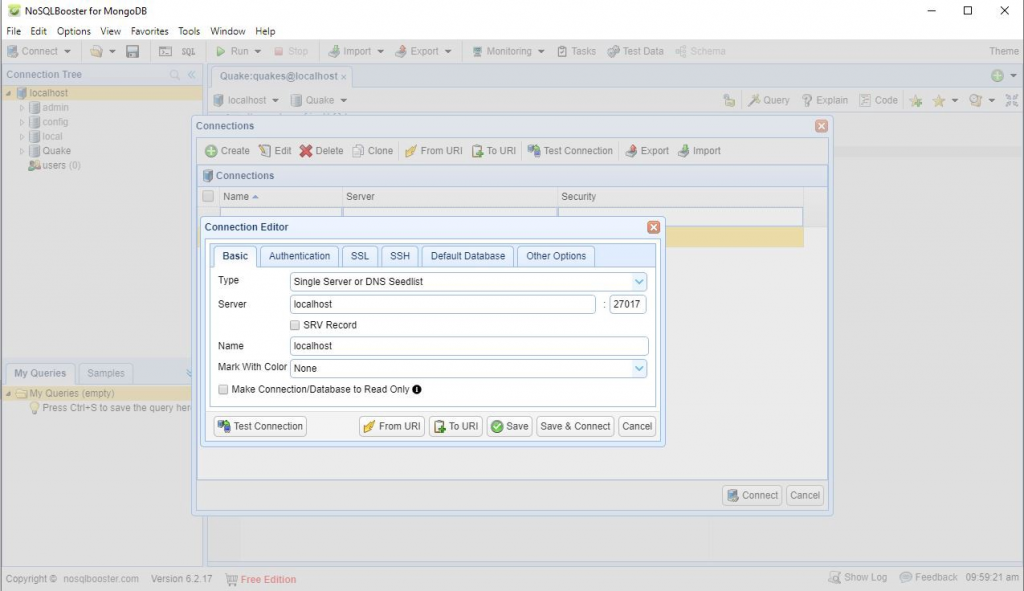
MongoDB 安装完成后,接下来我们可以使用 Jupyter Notebook 测试 PySpark。你可以简单地这样做:
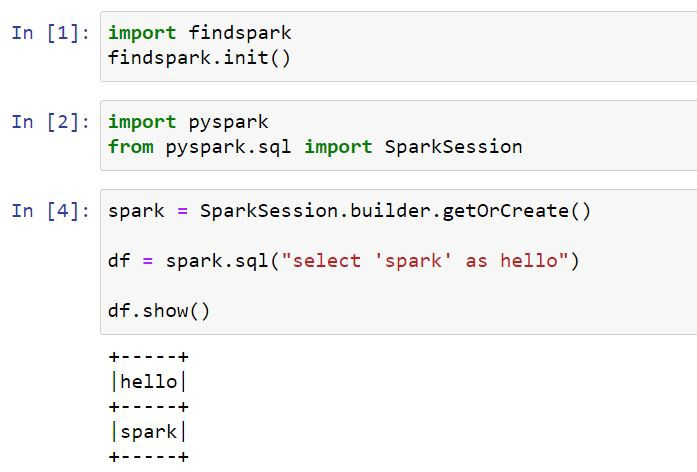
如果您看到“hello spark”消息,则可以验证 PySpark 是否与 Jupyter Notebook 一起成功运行。
好的,一旦我们的数据管道架构完全安装并且 PySpark 与 Jupyter Notebook 集成,现在我们就可以开始我们的数据科学项目了。
Comments NOTHING